Join us June 25th with Spritz — see how fiat and stablecoins work seamlessly in a real product. Register Here →
Behind the Scenes: How Modern Treasury Ensures Payment Reliability at Scale
We recently held a Tech Talk focused on how Modern Treasury ensures reliability at scale. Here, we take a deep dive into the discussion and the insights shared by members of our engineering team.
Payments and engineering teams at enterprises need to handle a wealth of complexity when building payment systems.
At Modern Treasury, we’ve created a robust infrastructure that facilitates seamless, real-time money movement, tracking, and reconciliation—especially for large enterprises dealing with high-volume, high-value, intricate transactions.
Having processed billions of dollars in payments through our platform in our nearly-six years, we've gained some valuable lessons along the way. Among the most important: how to ensure payment reliability at scale.
Here, is an abbreviated recap of our recent Tech Talk, moderated by Modern Treasury Product Manager Wayne Lin and featuring two of our engineering leaders, James Lim and Matt McFarland.
What does it mean to deliver reliability at scale? How do we even think about payments reliability as a concept?
James Lim: From a platform perspective, and specifically the request-driven part, reliability means that the API is available at four-nines or better (i.e., 99.99% of the time). It scales quickly, and it fails gracefully when there are errors or when there's an overwhelming amount of traffic. For the pipeline-driven part of things, reliability means that your jobs start on time, finish on time, and also can handle back pressure. And for storage, durability is what I care most about. Making sure that the data, once it's there, doesn't get lost.
Matt McFarland: The infrastructure and the foundational primitives, which James was just talking about—I tend to think about one level higher from the application point of view. Payment transmission is just one step of a life cycle. Really the payment life cycle starts when a customer loads a payment order into Modern Treasury, which is our way to represent a distinct payment.
We will eventually transmit that payment to the bank. That needs to happen reliably.
We need to be able to match that payment to any sort of data that comes back to us from the bank, whether that’s real time telemetry, like trace numbers returns, or eventually the transaction that correlates to that payment. And then finally, it ends with reconciling, which is a technical term in Modern Treasury’s product, to match that payment to that actual money movement and to the money that moves out of their bank account.
And so for us, the life cycle of a payment can happen overnight, or it can happen over several days. For us, reliability isn't just, “Did we accept a payment or not?” It’s really, “Was this payment supported from start to finish in a way that allows our customers to understand that payment in real-time for the duration of the transaction?”
If I'm doing my job right, customers can spend all of their time and energy focusing on their differentiation for their product. They don't have to worry about the details of whether their payments have succeeded or not, because Modern Treasury handles that for them.
What are some things that can make it challenging when we're talking about reliability in large volumes, at scale?
Matt: One of the things that is very common in payment systems is spiky load. You run payroll on Fridays. You do a monthly close and monthly settlement. It's not unexpected for us to have our largest day in payment volume on one day of the week or one day of the month. One thing I do is work with my teams to proactively schedule load tests and capacity management well beyond anything that a customer has ever thrown at us or will throw at us in the future.
I also think a lot about peak capacity or peak design. For Modern Treasury, being reliable means not just being everyday reliable, but being reliable for our biggest customers on their biggest days of the year and making sure that the payment life cycle I described before works at 10 times or 100 times load.
James: Reliability is very interesting as an engineering challenge, especially when we have to design systems to handle peak loads like what Matt was describing. Things that might be as simple as sending webhooks to our customers can get tricky at scale because it might work at one request per second (RPS) in my world, but when we started thinking about 5,000 RPS, we are in territory where it's very easy to overwhelm your customers.
In addition to enabling retries on those webhooks, we also want to make sure that our web hooks have exponential back off. We want to make sure that we have ways to queue up and buffer those web hooks and manage that back pressure against that. We're managing back pressure in our web hook system and are just being very careful about how we send those webhooks to our customers.
Zooming out, from an engineering and systems and architecture perspective, can give us a big picture of what the major systems that are really important for reliability?
Matt: When I think about simple architecture decisions, I think a lot about how we actually model transmissions to and from our payment providers, the banks. Something that we instituted from day one at Modern Treasury was a transmission proxy. We call it “Relay” internally. And Relay has one job, which is to manage every bit of data that flows to and from bank servers in a secure and authenticated fashion.
This lockdown proxy is also really good. And it has made our security team very happy because it makes their job so much simpler for bounded domain, and for where exactly every bit transmitted between ourselves and a bank is tightly regulated.
For service architecture, Relay is really so important, because, if we can ensure that data arrives to the bank securely and we get data from the bank securely, we can define really, really pointed and well-tested strategies for reliability with that. Because one biggest issues with reliability is if you have things happening more than once, you want to make sure that a payment arrives at the bank only once, or make sure that you download data only once.We do not want more than once, we want at most once.
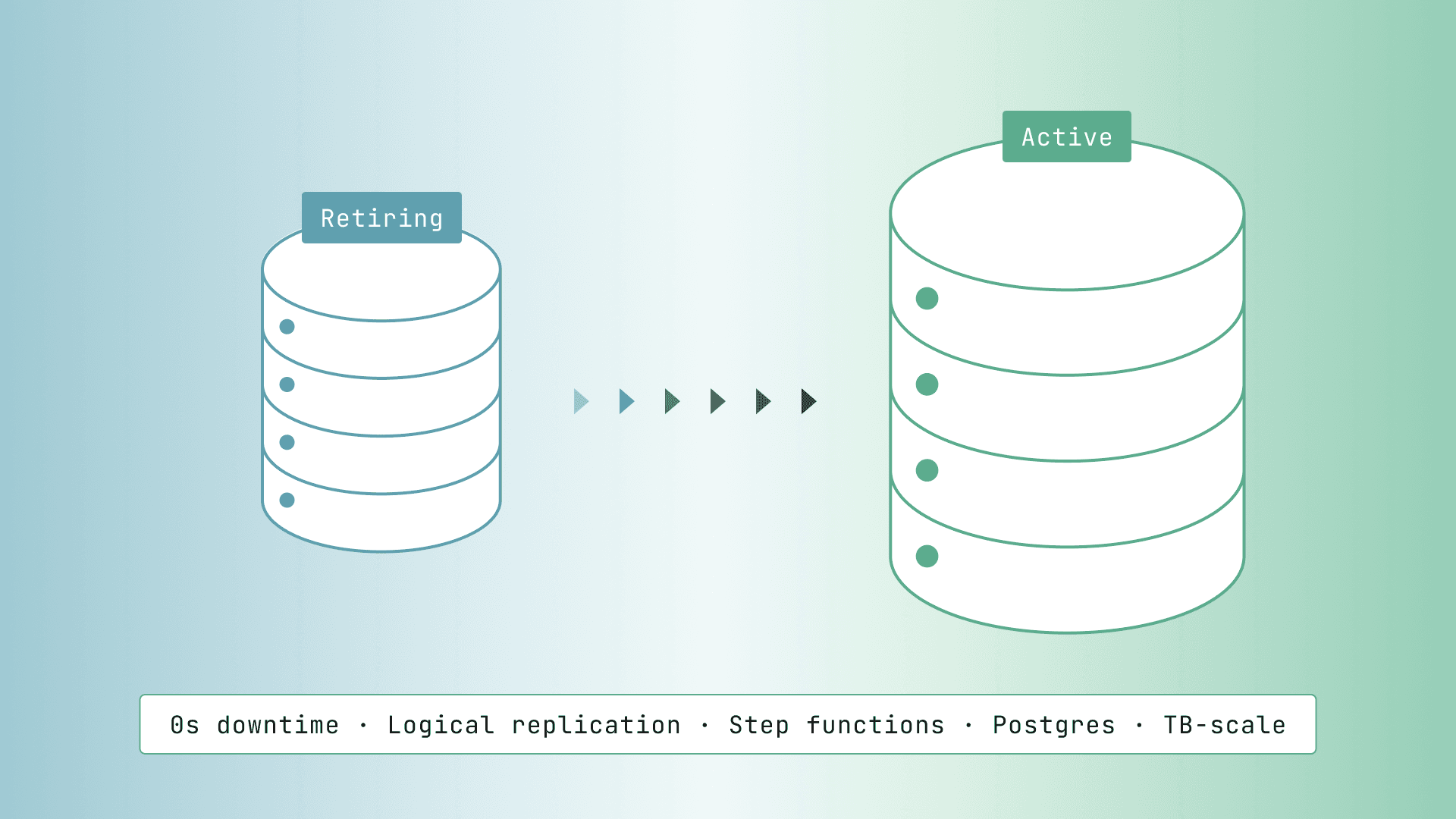
James: The Relay system was really a great idea. I spend a lot of time on security review and making sure that we have a lot of audit logging and inspection to make sure that it is safe and secured. In addition to the application and design decisions that Matt described on the platform side, my team has decided to implement acellular architecture. What that looks like is each cell is a copy of our entire infrastructure stack within that cell.
That way, if there's any kind of infrastructure issue within a cell, only customers that are in that cell are affected. And it is a very effective way to build blast walls between subsets of your customers.
Once we have that, we can also have segregated points where we deploy changes to one cell at a time. We can do capacity planning on the cell level. We can do linear scaling. If we bring on a large customer, we can just add another cell. And finally, that also allows us to provision dedicated tenancy for customers that really don't want to have any neighbors.
Matt: And on that note, for us, one of the primary challenges with reliability is the correctness times performance question. We have peak volume. We have performance concerns. And then we also need everything to be correct. And actually one of the best decisions that we made was setting our system up on a transactional database, Postgres.
We find that Postgres gives us incredible correctness and throughput. And so the cells architecture has been super amazing for us to hit peak throughput, especially for the load tests that my team runs. We can segregate one database per cell and that has really allowed us to reach global capacity metrics. That would be impossible with just one Postgres database. And that's a really good example of the application logic living together in a great synergy with the foundations that James is describing.
Can you share a bit more about how different customers may interpret the notion of reliability in different ways? Is it different depending on the type of customer?
Matt: I work with a lot of customers across a lot of different verticals, and I will tell you that someone running a wallet application on Modern Treasury interprets reliability differently than someone who runs payroll with Modern Treasury. A lot of it comes down to understanding the business use case and specifically what rules or requirements are subject to each business.
We've been talking a lot about payments, but Modern Treasury also handles inbound payments. And for customers, that can be the left hand to the right. Reliability means a lot for sending a payment, but it also means giving customers timely and accurate information for inbound payments.
We have a virtual accounts feature which helps customers attribute payments that are received to unique parties to help them to understand who sent the payment. And that is a reconciliation problem, you want to understand when the money lands in your account who that money came from. We want to give our customers as much information as they can to make an appropriate business decision for themselves.
We also talk a lot about seasoning payments in the ACH system. Seasoning isn't as relevant for payments that are received by wire, if you're funding a wallet from overseas, for example. The way that we handle this is by giving as much accurate information to our customers as we possibly can. And that means that we also spend a lot of time working with the underlying bank and payment providers to fully understand their specifications.
Going back to something you were asking earlier, Wayne, thinking about architecture. You can try and build an ideal architecture in a vacuum, but ultimately, if you're going to be going into payments, then you need payments to be reliable and you have to understand the actual payment specifications.
You really have to go deep on the rails. You have to understand how the network providers interact with each other. And there's no substitute for that. Modern Treasury has been a good partner for our customers and we will always be a good partner for our customers, acting as that expert who’s seen payments applied across verticals.
How does the interaction between your teams impact the reliability of your payments products?
James: I generally apply the approach of finding service level indicators and service level objectives to different layers of the stack. And these SLIs, once you have defined them, are kind of like guarantees that you provide to internal stakeholders and to external stakeholders.
For example, the API needs to be up 99.99% of the time—four nines. We define the probability or the percentage of jobs that are allowed to be interrupted if they are already started and we use those internally to hold ourselves accountable to a certain degree of quality.
That is the baseline for our team coordination. If any team who's responsible for a certain system is not meeting their objectives, their SLOs, then that triggers triage, improvement, fixing, debugging, etc. That's how I think about team coordination.
Matt: I can help James's team build that road map, because what I can do is specify, “Okay, across all customers, this is what the system actually has. Let's talk about peak capacity. Let's talk about latency or how long jobs can sit in queues.” And that has been a really effective way for our two teams to act on a hinge point or an interface point around building a reliable product at an application level.
Wayne: One thing I want to chime in and say here about the SLIs and SLOs that you were mentioning there, James, is like, it's almost like a translation. Because ultimately we need to say, “Well, what does the end payments need to be, how does it need to behave for customers? How are they using, again, different rails? And how do we then translate those into internal system requirements?” It’s the interlocking between upstream and downstream systems of understanding.
How did Modern Treasury's payments product evolve over time? And how important was it to get architecture decisions right from the beginning?
Matt: I'd love to talk about this one because I've been there for most of the evolution, which has been really fun. Modern Treasury started with a really simple premise, which is to be very good at transmission of file based systems. That really comes out of the founders' experience at their last company, running an internal version of Modern Treasury that ran about a billion dollars a month as part of mortgage servicing. When I joined Modern Treasury, one of my first projects was to work on and augment Relay, so that it could handle HTTP requests to power the RTP product.
RTP is generally always available as an API based system for banking products. And that's something I've seen come online over time and that's also how FedNow is being designed today. Relay, which was a file based proxy, also turned into an API proxy.
That was a huge step function change. In this case, instead of a Nacha file or a Fedwire file, it's a JSON payload, and it transmits that through Relay and Relay transmits that request to the bank and then the data comes back in the same format.
I do think there's one interesting architectural evolution here, which is that the monolith needs to be able to handle a real time response—-different error codes or timeouts, for example. That has been a large shift in how our application has had to handle errors or map over the entirety of responses, so files are fundamentally asynchronous and the API is fundamentally synchronous.
That has been an interesting change for our architecture because for API requests, it's the error handling but it's also handling webhooks. You can suddenly have a huge amount of data that a bank is pushing to you in the form of webhooks that you have to handle scalably.
I would say that the best takeaway has been not to think of these as disparate systems but to think of them as the same system. Instead of reading responses from HTTP, just think about them as reading a file that's JSON. That has been a principle that scales for correctness and for fault tolerance, because then we can actually start thinking in an asynchronous way which scales a lot better for us.
Wayne: Just to add on here, but to address the question around how important it is to get these decisions right the first time, some of these decisions definitely are harder to change as you have an online system that is supporting a lot of volume. I think part of today's talk is even just sharing our learning so that hopefully you in the audience can get it right earlier on. And I think because we definitely benefit a lot from some of these key decisions up front.
Next Steps
To hear our full discussion about building for reliability at scale—including more audience Q&A—watch the recording of this Tech Talk here.
If you’re ready to learn more about how Modern Treasury’s operating system for money movement can help your business reliably manage payments, tracking, and reconciliation at scale, reach out to us.
Get the latest articles, guides, and insights delivered to your inbox.
Authors