Join us June 25th with Spritz — see how fiat and stablecoins work seamlessly in a real product. Register Here →
How to Scale a Ledger, Part I: Why Use a Ledger Database
In the first part of this series, we’re looking at why any company that moves money at scale should have a ledger database as a single source of truth.
At Modern Treasury, we work with some of the largest fintechs and marketplaces in the US. We started with an API that lets companies integrate directly with bank payment rails. As our customers scaled over time, however, we quickly realized our they needed a way to track the high volumes of transactions and balances in their platforms.
Companies that move money need a ledger: a scalable, double-entry database for financial transactions and balances. It seems simple. But as developers who work with money know, and as the news will attest to, this is actually a complex computer science problem. This 6-part series summarizes what we've learned helping companies implement ledgers that are reliable, consistent, and fast.
Why Use a Ledger Database?
As financial services increasingly become embedded into mobile and web apps, more companies are facing the challenge of storing, transferring, and converting money. Typically, most developers start by embedding financial logic directly into their domain models:
- The price of a ride share is a property of the ride
- The monthly payout to a gym is a sum across bookings
- The amount left to pay on a loan is stored on the loan object
Why Traditional Models Fail At Scale
As your user base grows and you embed financial services deeper into your product, four common problems arise:
- Reporting Needs Expand: Companies need more sophisticated financial reporting as they grow. Every movement must be immutably recorded, keeping track of the source and destination of each dollar for compliance and financial audits.
- Data Becomes Fragmented: Stitching together a clean history of financial events becomes impossible as data models become more complex, companies migrate to service-oriented architectures, or multiple fintech SaaS products that aren’t natively integrated are introduced.
- Performance Slows Down: Performance degrades as the number of users increases: payout cron jobs miss deadlines, card authorization checks lag, and other bottlenecks emerge.
- Failure Scenarios Increase: Overcharging, insufficient funds, fraudulent transactions, and other reasons for rejected payments are more frequent and difficult to reverse without a clear audit trail.
All of these problems can be solved with a ledger database.
Core Features of a Ledger Database
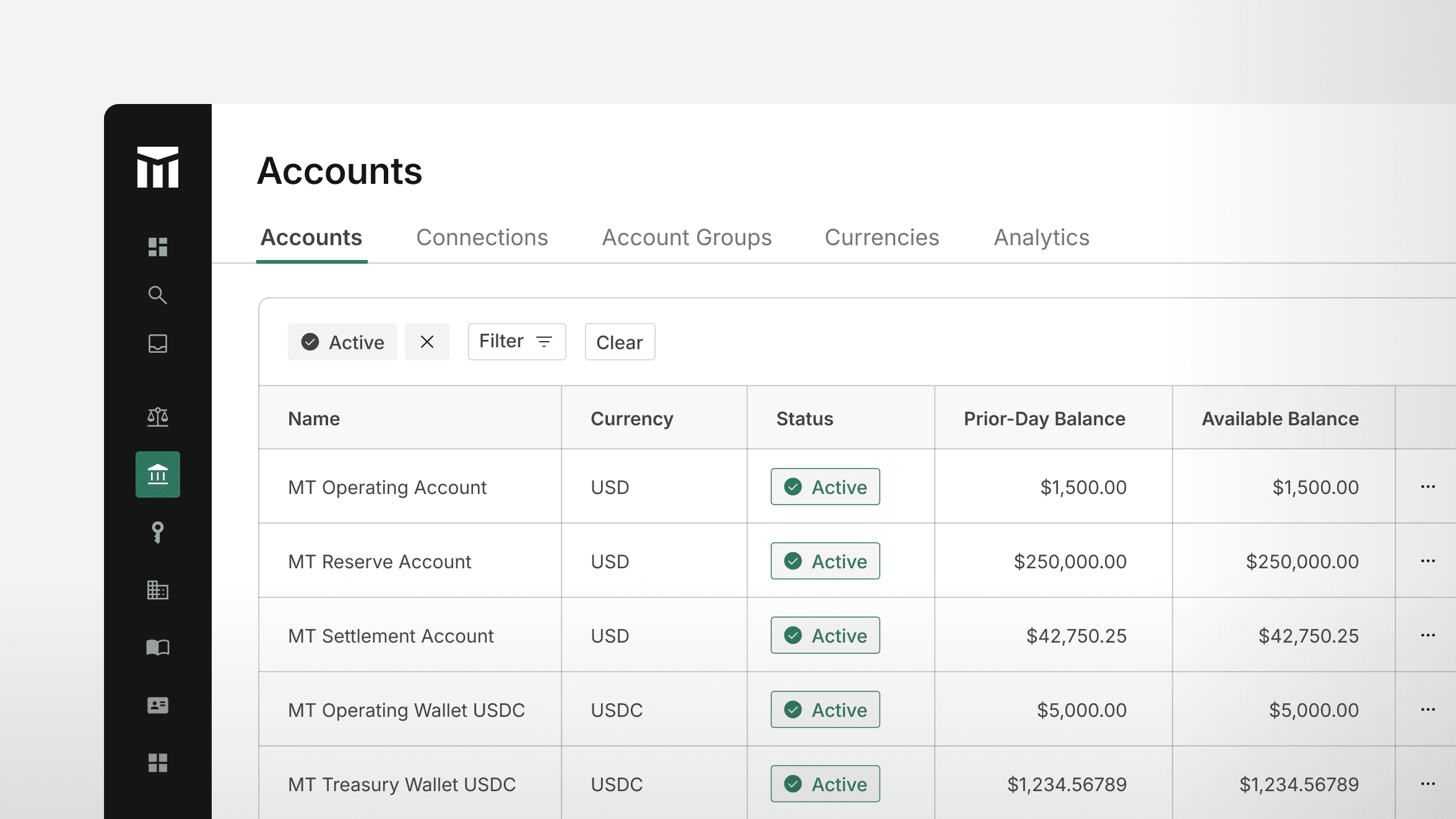
At its core, a ledger database is a simple data model:
- Accounts: Represent discrete pools of value
- Transactions: Atomic monetary events that affect accounts
- Entries: Individual debits and credits that make up a transaction
A common refrain from engineers is: “A ledger is simple to build, but the business logic on top of a ledger is complex.” In fact, a well-designed and scalable core ledger database can simplify business logic and reduce time to market.
A scalable ledger database provides these guarantees:
- Immutability: Every change to the ledger is recorded such that past states of the ledger can always be retrieved, and the changes are permanent and queryable.
- Double-entry enforcement: The API enforces that money cannot be moved without specifying the source and destination of funds, following double-entry accounting principles.
- Concurrency controls: Money can’t be double-spent, even when transactions are written out of order or in parallel.
- Efficient aggregations: It supports fast compute aggregations of financial events, such as the sum of all events in a particular time frame.
We aim to show why any company that moves money at scale should invest in a ledger database.
The Fintech Translation Problem
Product engineers speak the language of their domain models—orders, rides, and bookings. As their products scale, these engineers must translate another language from the finance team—credits, debits, assets, and liabilities. Invariably, engineers get assigned the dreaded task of translating our domain models into double-entry accounting.
This is no easy feat. Financial events are often:
- Fragmented and from disparate sources. The app may rely on multiple fintech SaaS solutions (like issuer processors, card processors, and ACH processors). App data models may be spread across multiple databases and be owned by different teams of engineers. Corporate bank accounts contain fungible cash—attributing each dollar to its source is not possible.
- Speaking different languages. Every fintech SaaS product has its own set of APIs that require separate integrations. App data models may be a mix of new and legacy systems, and documentation is likely scarce. As we know well at Modern Treasury, banks send transaction information in a wide variety of arcane formats that are difficult to parse.
- Generated from mutable underlying records. None of the sources of financial events have a rock-solid, consistent way to reconstruct why a pool of money was a certain value at a certain time.
Many companies that move money as part of their products take the translation approach, however. Finance teams learn to accept that reconciliation can only happen accurately at the aggregate level. Attributing money movement back to the source application event is always a manual task, and in some cases, isn’t possible.
Real-World Consequences of Ledger Errors
Missing or inconsistent attribution can cause serious issues.
A product leader at a large consumer payments company recently told us that every month, the finance team would notice that a few million dollars had gone missing in their ledger, kicking off a mad scramble to figure out where the money had gone.
Every engineer that has built money moving software has a similar story. In these stories, it’s not the funds that go missing—they’re still sitting in a bank account. It’s the attribution that’s lost—the database record of who they actually belong to.
Even worse, these ledger errors ultimately become public:
- A small business customer on a marketplace platform will ask questions when a sale they expected to appear in a payout isn’t there.
- A digital wallet customer will churn if they send money to another customer, but it never arrives.
- Regulators will ask hard questions if a loan customer initiates an on-time payment, but your system marks them as past due because the payment was recorded late.
The solution is to enforce double-entry and immutability at the source of financial events.
Just like a unique index in a relational database gives engineers confidence, a ledger database that enforces double-entry rules makes it not just difficult for money to go missing, but architecturally impossible.
Why Most Companies Delay, and Why You Shouldn't
Why doesn’t every company that moves money use a double-entry ledger to power their products? Because building a ledger that both follows double-entry rules and is performant enough to run live apps is a difficult engineering problem.
Building a scalable, reliable, and performant double-entry ledger system takes:
- Years of effort and dozens of senior engineers to migrate single-entry systems
- Deep domain knowledge of accounting and applying that to systems architecture
- Ongoing maintenance and reconciliation tooling
Only recently has it been possible for companies to get the benefits of double-entry accounting without a massive up-front build and costly maintenance by using purpose-built ledger databases like Modern Treasury Ledgers.
Next Steps
This is just the first chapter of a broader technical series with a more comprehensive overview of the importance of solid ledgering and the amount of investment it takes to get right.
If you want to learn more, download the paper, or get in touch.
Read the rest of the series:
Get the latest articles, guides, and insights delivered to your inbox.
Authors

Matt McNierney serves as Engineering Manager for the Ledgers product at Modern Treasury, and is frequent contributor to Modern Treasury’s technical community. Prior to this role, Matt was an Engineer at Square. Matt holds a B.A. in Computer Science from Dartmouth College.