How to Scale a Ledger, Part III: Transaction Models
In the third part of this series, we'll look at how Transaction models enable atomic money movement and enforce double-entry.
Updated on August 22, 2025.
This post is the third chapter of a broader technical paper, How to Scale a Ledger. In Part I, we covered why you should use a ledger database, and in Part II, we mapped common financial events to double entry primitives like Accounts and Entries. In this chapter, we look at a transaction model to enable atomic movement.
Why Transactions Matter in Ledger Systems
While Accounts and Entries within ledger databases provide an immutable audit trails of balance changes, they aren’t enough on their own. Without a Transaction object, it’s possible to create inconsistent states if only part of a money movement is recorded.
A well designed transaction model provides:
- Atomicity: All Entries must succeed or fail together
- Consistency: Prevents partial state changes
- Double-entry enforcement: Ensures balanced Entries for every transaction
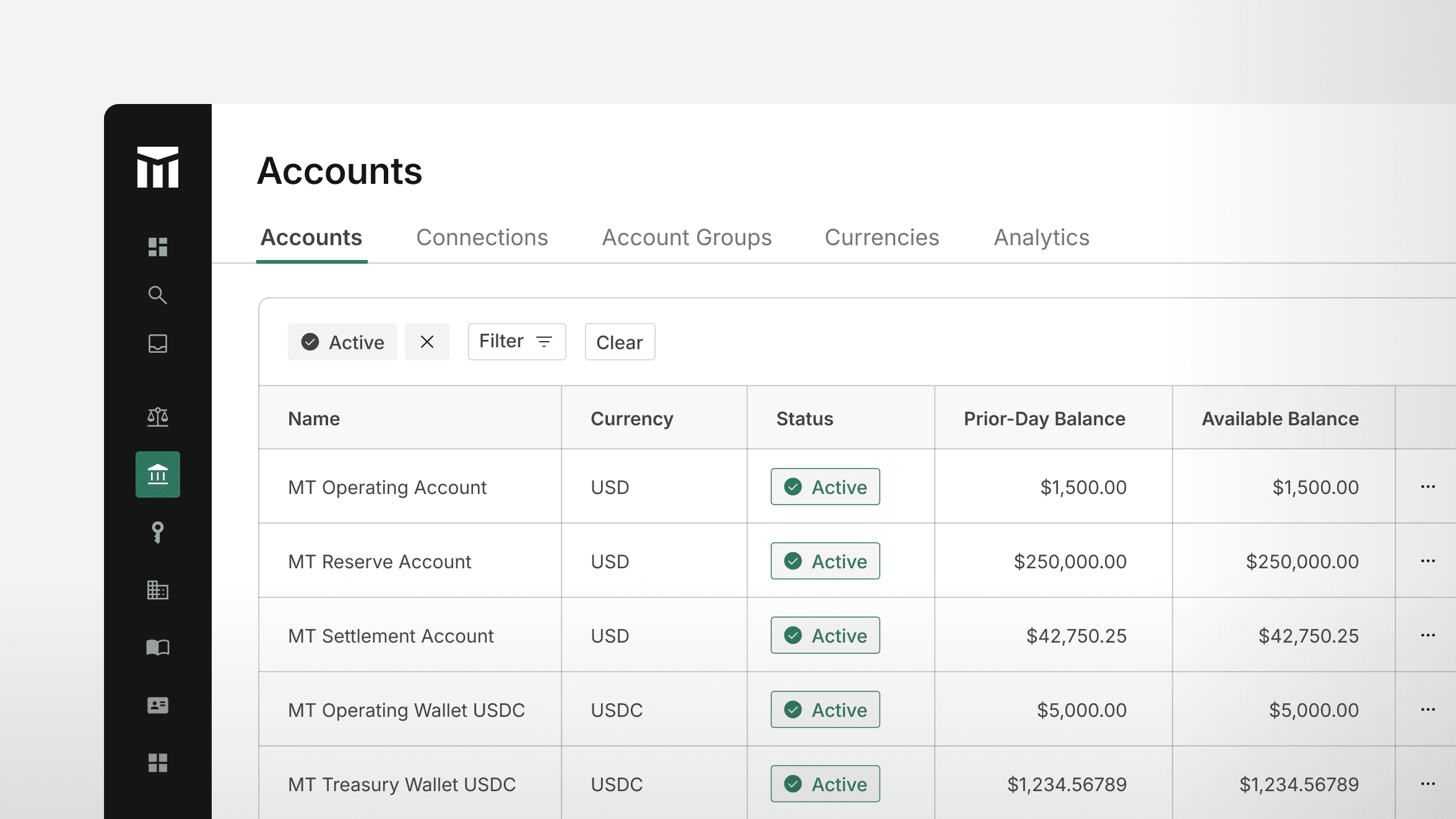
Transaction Schema: Digital Wallet Transfer Example
Consider a simple transfer of money between accounts in a peer-to-peer wallet app. Let’s say Bobby sends Alice $10; we can represent that transfer as two Entries: bobby_entry and alice_entry.
Imagine that bobby_entry was successfully written, but the corresponding alice_entry failed to write (maybe the database was having network issues). Now the ledger is in an inconsistent state—Bobby was debited money, but Alice didn’t get anything. Money is lost.
Transactions solve this consistency problem by allowing us to specify groups of Entries that either must all succeed or all fail. In order to guarantee atomicity, all the non-discarded Entries on a Transaction must share the status of the Transaction. This ensures that all Entries progress in status at the same time, all-or-nothing.
A Ledger API should only allow clients to directly create Transactions, not Entries. This limitation helps ensure clients don’t run into consistency problems. However, that means a Ledger API must manage creating Entries itself. There are three operations to implement, corresponding to the possible states of the Transaction:
- Pending (initial state)
- Posted (finalized)
- Archived (canceled before posting)
Creating a Pending Transaction
This is generally the first step in the lifecycle of a Transaction. The system persists the debit and credit Entries as pending, but the transaction is not finalized.
Posting a Transaction (Finalizing It)
Since Entries are immutable, when we move a Transaction from pending to posted, we need to:
1. Discard the pending Entries (bobby_entry_1 and alice_entry_1).
2. Create new posted Entries. This preserves immutability: posted Entries are never modified.
Archiving a Transaction (Canceling It)
Posted Transactions are immutable, and so cannot be archived. So what if the transaction was canceled?
Pending Transactions can have their status changed to archived, following a similar process to posting.
1. Discard pending bobby_entry_1 and alice_entry_1.
2. Create new Entries with archived status.
Next Steps
This is the third chapter of a broader technical paper with a more comprehensive overview of the importance of solid ledgering and the amount of investment it takes to get right.
If you want to learn more, download the paper, or get in touch.
Read the rest of the series:
Get the latest articles, guides, and insights delivered to your inbox.
Authors

Matt McNierney serves as Engineering Manager for the Ledgers product at Modern Treasury, and is frequent contributor to Modern Treasury’s technical community. Prior to this role, Matt was an Engineer at Square. Matt holds a B.A. in Computer Science from Dartmouth College.